Running Crews on NVIDIA’s Newest Model —Here’s What Happened
We tested NVIDIA’s new Llama Nemotron Super 1.5 inside CrewAI — and had it running in minutes and ran particularly fast in CrewAI Flows.
 João (Joe) Moura
João (Joe) Moura

There’s no shortage of model launches these days. But this one caught our attention.
The newly released NVIDIA Llama Nemotron Super 1.5 — a production-grade, open-weight model designed to run fast and flexibly in enterprise environments. Naturally, we threw it straight into CrewAI.
TL;DR?
Easy to host
Seamless to integrate
Works well for structured flows
Some tool-looping without constraints
Best used with CrewAI Flows
Here’s what we found. You can find our demo using CrewAI Flow for low level control and speed here.
Live Workflow in Minutes
We got the model up and running on 4 NVIDIA H100 GPUs using vLLM with barely any friction. No weird configs, no fine-tuning hurdles.
Once hosted, plugging it into CrewAI was as easy as:
llm = LLM(
model="text-completion-openai/nemotron",
temperature=1,
top_p=0.95,
api_base="<MODEL_API_BASE>",
max_tokens=10000,
)Pro tip: There is an optimum temperature range (~0.6 - 1.2) that got us better results in our multi-agent orchestration tests.
Crews Full Prompt Control, Tooling Support
One of the things worth highlighting is that CrewAI gives you full control over its internal prompts.
For this test, I replaced every internal instruction — and Nemotron handled it well.
Tool use is solid, and both with and without reasoning it was able to get work done as an agent, even being a 49B model, all it took was some slightly prompt adjustments on the agent to keep things simple and provide clear instructions.
CrewAI Flows: The Right Fit
The best experience was when we dropped this model into CrewAI Flows — our low-level, modular orchestration layer, it ran particularly fast!
Flows are built for real-world automation:
Sometimes you just want an LLM to enrich an email.
Sometimes you need full-on agent collaboration.
And sometimes? You need both.
With Flows, you don’t have to choose. You orchestrate what the workflow demands — nothing more, nothing less.
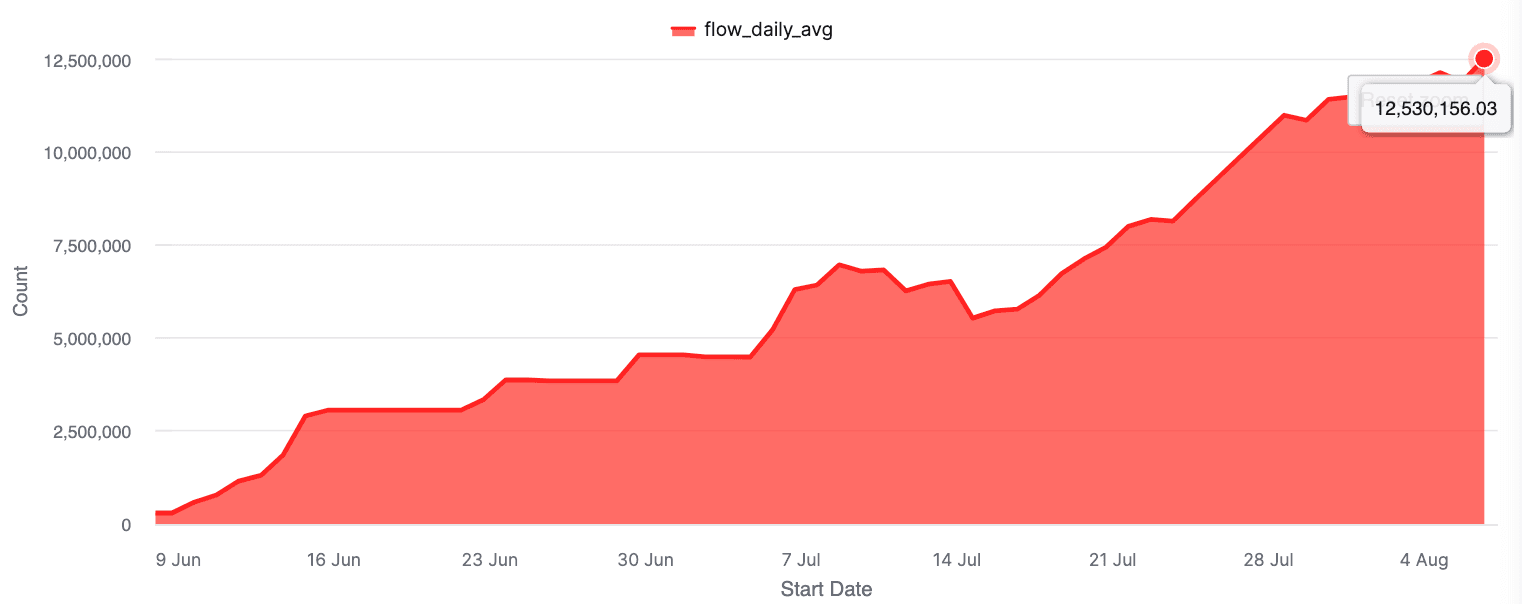
CrewAI Flows now power 12,000,000+ (12M) executions/day across use cases from finance to federal to field ops.
The Bigger Picture: Structured Agency
Most platforms still push a single mode, what influence the models choices you have:
Agents
Graphs
Chatbots
But real teams work across a spectrum of agency, and that can be particularly helpful for models like NVIDIA Llama Nemotron Super 1.5. This spectrum mentality allows you to start simple and grow from there:
Rules-based flows
Ad hoc LLM calls
Agent delegation (when needed)
Fully autonomous crews (when ROI is real)
You don’t need a graph to send a Slack message.You don’t need a 50-token prompt chain to enrich an email.You just need the right structure at the right time. CrewAI Flow gives you that — and models like Nemotron slot right in.
Final Take
NVIDIA’s Llama Nemotron Super 49B is a deployable asset — fast to spin up, friendly to orchestrate, and ready to plug into workflows.We’ll keep testing it in Flows, and will be sharing more live demos soon.In the meantime, big props to the NVIDIA team for shipping a model that makes a real impact on enterprise AI.


